ハングル工房 綾瀬 - パソコン・ノート (文字コードの話)
ハングル工房 東京綾瀬 - パソコン・ノート (文字コードの話)
Hangeul-Lab Ayase, Tokyo
Ken Mizuno
ハングル工房 綾瀬店 ホームへ
パソコン・ノート 全体目次へ
Mail to home master: Ken Mizuno
文字コードとフォントの関係
「文字コード」とは、「その文字をあらわす数字」のことです。
少し前の中国の電報は、電報局間では数字が交換されていました。例えば次の数字の羅列
3055 6851
は、「水 野」を「中国電報文字コード」で表現したものです。電報局の職員は、まず漢字を目で見て手作業で数字に変換し、その数字を「電信」で送信し、受け取った局では職員が再び手作業で漢字に復元したうえで、受け取り人に配達される、と。
厳密に言うと、この1つ1つの文字に当てた数字が「文字コード」または「コード」、そのコードと実際の「文字(つまり、絵)」の対応関係を表にしたものが「コード表」で、このコード表に出ている「文字(絵)」の「集合」を「文字セット」と呼びます。
この「コード」と、それの意味する「文字(絵)」の関係は恣意的で、ちょうど言葉とその意味の関係が恣意的であるのと同じです - 例えば「ソン」と言えば日本語では「損」を意味するのに、朝鮮語では「手」とか「客」とかを意味するなど、コトバとその意味の結合関係には何の理由もない - 同様に、コード(という数字)と、それが意味する文字(絵)の関係は、「誰かがそう決めたからそうなっている」だけであって、それ以上の何の意味もありません。
それから、「コード」は必ずしも「数字」である必要さえなくて、単なる「記号」であってもかまいません。例えば、今では使われない「モールス符号(トー・ツ・ツ・ツ・トー・トー)」は電信回路から耳へ、その耳で聞き取った「コード」を、人間が手で鉛筆で「文字」に復元するものでした。
コンピュータ上の文字は、その 99.99%が「文字コード」で表現されます。このコードは 必ず「数字」表現であり、しかし人間には数字ではわかりませんから、コンピュータ自身の機能を使って 常に「文字」という「絵」に復元させてから、画面に表示することになっています。
この「絵」を、「フォント」と呼びます。
MS-DOSの時代、ある言語の文字の「フォント」つまり字体は、機械ごとに決まっていました。例えば NEC PC-9801は「漢字ROM」というハードウェアを中に持っていて、この中には「JIS漢字」の絵がぎっしりつまっていました。しかし、そのセットは1セットだけでした。IBM-PCも同様に、英文字の「フォントROM」を持っています。IBM-PCらしい字体で、それが所有者のステータス・シンボルにもなりましたが、それはやはり「ただ1種」だけでした。
これと異なる方向をもったのが、Machintoshでした。この機械には、英文字のフォントROMさえ乗っていません。「文字」という名の「絵」は、ソフトウェアとして供給されました。だから、Macの基本的なところでは Chicagoとか Osakaとかいう名前のフォントが使われますが、他の部分ではまるで異なる字体が画面に出ます。
それが、「アプリケーションによるフォント切り替え機能」です。同じテキストつまり同じ文字コードの羅列が与えられても、ソフトの選択によってそれがタイプライター文字になったり、新聞活字体で出たり、変態少女文字になったりする、そういうことをユーザが自分で選択できるようになったわけです。この「字体」は、ユーザがそういう「フォント・セット」を、勝手に自分で用意すればよいのです。
同じことは、Windows 3.1でも実現されました。これ以後は、Windowsでも Macでも、いろいろな字体が使えるようになりました。
以上のまとめ:
- 文字コードとは、数字のことである
- その文字コードをコンピュータは「絵」として表示する。この「絵」をフォントと呼ぶ
- 文字コードとフォントの絵の間には一定の対応関係があるが、この関係は恣意的に決められたものであり、その対応関係には「意味」がない
- フォントとはつまり「どんな字体か」ということである。「字体=フォント」ごとに、Macや Windowsではいくつでも、何種類でも異なる「フォント」を用意することができる
英文 ASCII 7ビット(8ビット)系
現実のコード表をながめてみましょう。
基本の基本は、まず英文字「だけ」の ASCII (American Standard Code for Information Interchange) 7ビット・コードです。「アメリカ」嫌いな人も、これは了解されたい。なぜなら、コンピュータの出生地はアメリカなので、「すべての文字コードはアメリカの文字系を出発点とする」からです。
次に、「7ビット」とか「8ビット」とかいうのは、「コンピュータ」が「2進数による数字表現」しか扱えないことと関係します。「2進数」というのは、小学校か中学の算数・数学で習ったと思いますが、「電球が点灯していれば数字の1と、点灯していなければ数字の0とみなす」、あれです。これを7個 並べれば7ビット、きりの良い偶数にして8個 並べたのを「8ビット=1バイト」と言います。この「8ビット」で、28=256種類の文字を表現できるわけですが、アメリカ語では 256文字は必要がなかったので、ASCIIコード系はその半分、128文字しか決めていませんでした:
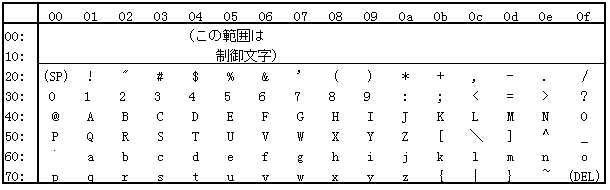
表の見方:
タテ軸は8ビットの上位4ビット、横軸は下位4ビット。
4ビットで 24=16個を表現できるが、そのため「普通の十進数」ではなく「16進数」で表現してある。なお「2進数と16進数の関係」は、この講義の 付録 を参照のこと。
例えば、英文字の「A」は、上位が 40、下位が 01 なので、この文字のコードは「41」です。同様に小文字の「a」は上位が 60、下位が 01 なので、文字コードは「61」です。同じように、「Z」は 5a、「z」は 7a。
こうして「16進数」が出てくることに抵抗を覚える人もいるはずですが、今は「これはそういう記号なのだ」と考えてください
この表で、注目してほしいのは「制御文字」という部分があることです。
「制御文字」とは何ぞや?
英文タイプライターを覚えていますか? 「文字の出ないキー」がありましたね; 例えば「改行」キーをたたくと、紙をはさんだプラテンがギー、がっちゃんと戻って、それから1行分だけ回転して、次の行をたたく準備ができました。この動作は (1) Carriage Return つまりプラテンが紙の左端に戻る動作と、(2) Line Feed つまり1行分だけ紙送りする動作の、2つからなります。
この他、電動タイプライターでは、Form Feed:「紙をいったんはきだして、次の紙を入れる」というのもありました。それから、TABという「文字」があって、これは「文字」は出ないが「ある幅だけ空白のまま移動」、スペース・キーというのは「1文字分だけの空白」という「文字」でした。
ASCII 7ビット・コードの「制御文字」には、こういう「文字として目には見えない」コードが含まれています。この種のコードが 32+個。ご参考までに、CR は 0d、LF は 0a、それから FF は 0c、TABは 09、スペースは 20 になっています。
東洋語(日本語、中国語、朝鮮語)の「2バイト系」文字と文字コードが使われるようになっても、ASCII「制御」文字は、「2バイト系」の中でそのまま使われています。言い換えると、例えば MS-DOSや Windowsのファイルには、改行ごとに CR LF という2「文字」が、Macでは CR 1つだけですが、現在も「ここで改行表示しなさい」という意味で、どんなテキストにも埋め込まれています。これも「文字コード」の一部である点を理解できれば、この項の目的の大半は達しました。
なお、くどいようですが、「目に見える文字の形」=「フォント」は、昔から機種ごとに異なっています。
ASCIIコード系の制定当時、「フォント」は「テレタイプ」の鉛活字、つまり英文・機械式タイプライター型の「端末」が想定されていました。テレタイプで送った文書が受け取り側にどう見えるかは、ただひたすら受け取り側 端末の鉛活字の品質(例えば、その すりへり方とか、リボンが薄くなったとか)によりました。
これがやがて、初代 IBM-PCの「IBMらしい文字」に変ります。そして、Macintochの Chicago書体、現代の東洋語 Windowsや Macの字体へと、「見た目」はドラスチックに変化しています。が、少なくともアメリカ語のコード系そのものは、ASCIIコードが成立した 1960年代から変化はありませんし、現代の東洋語コード系も、その基礎の上に成り立っていることを、ここでは理解してください。
日本語 JIS(半角)8ビット系
ASCII 8ビット(7ビット)系が「256文字の半分」しか定義していないことは、日本では好都合なことでした - 残りの 128文字を日本語に使ってしまえ!
こうすると、「8ビット=1文字」をムダなく使いきることになります。
もちろん、そのための不都合も起こりました; 例えば、アメリカのソフトは、文字の最上位ビットは必ず「0」だと思っていますから、この部分をソフトが勝手に使うことがありました; 昔マイコン少年だった人は、アメリカ製のOSの中には「ファイル名は英文字だけ、ファイル名の末尾は最上位ビットが立っている」というのがあったのを、覚えていると思います。
しかしそれはそれ。
256字の半分は残っているわけですから、これを「国」レベルで規格にしてしまえば勝ちです。JISつまり日本工業規格は、残りの 128文字の一部に「半角カナ」を決めました。1980年ころの日本の8ビット・パソコンでは、既にこれが有力でした:
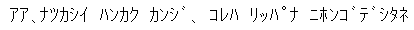
この「JIS 8ビット」系は、本来は「カナ」だけではありません(だって、カナはどうせ 50余字しかないのだから、まだ余りがあります)。だから、本来は郵便マークとかいろんな「絵文字」も入っていました。が現在「半角カナ」を使う世界では、この「カナ」以外の文字は意味を失っています:
どういう意味かというと、その後、パソコンで「漢字」を扱う必要が出てきました; この「漢字」がくせもので、とても 200字や 300文字では追いつきません。仕方がないので、漢字は連続2バイトを使って表現します。
そのとき、過去の、既存の1バイト ASCII英文字や半角カナと混在・区別が必要になりました。
中間をはしょってしまえば、いま生き残っている「JIS 8ビット」のコード表は、次のようになっていて、これが(Windows、Macを問わず)日本のパソコンで使われています:

この表の上半分は、ASCIIとほぼ同じです。
が、下半分にはカナがあり、その前後に「Shift-JIS 第1バイト」があることに注目:
現代の日本のパソコン(のOS)は、この範囲の文字に出会うと「これは8ビット文字ではない、2バイト連続する漢字コードの前半だ」と 判断します。これが「全角」日本語漢字です。
この「全角」漢字が扱えなければ パソコンなど実用にならないようになってから、日本の「パソコンの」コード系は、すべてこれに収斂してしまいました。
追記:もしあなたが、仮に「文字コード系の簡潔さ、美しさ」(の程度)ということに興味がある人なら、このあたりから首をかしげるはずです ... とても巧妙だが、何か、不自然な感じがしませんか?
この「変な感じのする漢字処理」は、我々の直感通り、専門家たちも気に入ってはいません。その話は、JIS 漢字コードのところで再度 説明します。
韓国の KS(半角)8ビット系
韓国でも、「半角カナ」と似たようなことが、一時は行われました。つまり、ASCIIが未定義のまま残した(より正確に言うと、ASCIIは7ビット定義なので、+1 ビットが余っているので)残りの 128文字に、ハングルを入れよう!
ただ、ハングルというのは困ったことに、24の字母さえ定義すればよいというものではありません。KS工業規格になったのか規格案に止まったかはわかりませんが、この規格では、24文字のハングル字母を並べただけでした - コン・ビョンウ式タイプライターじゃあるまいし、phur-eo-sseu-gi「ばら打ち」ハングル文なんて:
こんなの誰が使うもんですか。
結局こんな「規格」は無意味で、忘れられました。韓国は、コンピュータを作る各メーカーが、勝手なハングル文字コードを勝手に作った「規格乱立」時代に入りました。それらを統一したのが、現在の KS「完成型」および「組み合わせ型」2種の規格ですが、それはさておき、
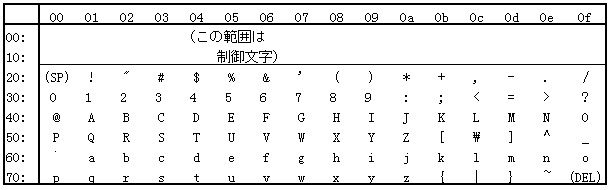
ともあれ、KS 8ビット・コード系は、意味を失いました。結果的、現実的に、韓国の8ビット系は アメリカの ASCIIと同じ英文字 128個に限られます:
8ビット系の練習問題:
以上の ASCII, JIS, KS の1バイト・コードの前半 128文字は、ただ1つを除いて正確に同じです。この「ただ1つ」のちがいを指摘しなさい。また、アメリカ版、日本版、韓国版 それぞれ MS-DOSや Windowsが、「見た目」が大きく異なる「ある要因」について説明しなさい。
練習問題の答え:
文字コード 5c だけが、みな異なっている点。
ASCII にはアメリカの "$" が既に含まれているのに、日本も韓国も それは温存した上で、一方アメリカの「バック・スラッシュ '\'」を犠牲にして、その位置に自国の通貨記号を入れたのでした。その結果、MS-DOS/Windows では、ファイルの「パス名」の見えかたがちがいます。それから、DOS/Windowsにかぎらず、プログラム言語の中で「見えかたがちがう」現象が出てきます:
どれが見やすいかは、まあ、明らかなんですが...(僕は今でも、韓国版の Windowsを使うたびに腹が立ちます。40代になると、これはすごく見にくい!)
付録:ビット、バイト、2進、16進...
まず、「普通の 10進数」を考えましょう: 「数字」は0から9までの 10個しかありません。これでは困る。9より大きい数字はどうするの? 「たくさん」ですませたのが、「0の発見」以前の人類でしたね。
「0の発見」以後、数字には「桁上がり」という革命的手法が導入されました。これによって、2桁で0から 99までの 100個の数を表現できます。
3桁あれば、0から 999までの 1,000個の数字を表現できます。
4桁で 0から 9999まで、10,000個、
5桁で 0から 99999まで、100,000個、
つまり、普通の 10進数で N桁を用意すれば、
10N個の数
を表現できるわけですね。
コンピュータが、「電気あり:1、電気なし:0」という「デジタル」原理で動いていることは、ご存じの通り。このやり方では、「数字には0と1の2種類しかない」です。「2」から上の数字はどうするの? 「桁上がり」させます。
紙の上では、「普通の数字」は手で2桁書けばよろしい。
「デジタル」な2進数では、「電気あり/なし」の電線を、桁数だけ、物理的にたくさんならべます。この電線を8本ならべたのが「8ビット」、32本ならべたのが「32ビット」コンピュータです。
(おことわり:コンピュータを「ハイテク」だと思っている人は、まずその誤解を捨てなさい。「32ビット」を実現するために、コンピュータは 32本の電線を平行に走らせるという、おそろしく原始的なことをする機械です。電話線がたった2本の電線で世界の果てまでつながっているのに対して、コンピュータはその機械の内部で 32本、64本といった電線をはりめぐらせる、そういう泥臭いことをやる機械です)
2進数とは、実は何のことはない、玉1つしかないソロバンにすぎません。普通のソロバンは玉が5つも6つもありますが、2進のソロバンは「玉1つだけ」。その玉が電線の数だけ横に、やたらに長いだけです。例えば8ビットなら、こういうやつですな:

このソロバンの玉は、0100-0001 と読みます。0と1ばかりで長くてしょうがないので、4桁で区切りを入れるのがミソです。実際、8桁では長くて困るので、今は4桁だけで話を続けます。
練習問題:
0000から 1111まで 16個の2進数を、ソロバン抱えたつもりで鉛筆をもって紙に書いてみなさい。そのとき、それぞれの数字が「普通の 10進数」ではいくつになるかも、隣に記入しなさい。
練習問題の回答:
ついでに「16進数」も掲げておきます:
| ◆◆◆◆ | 10進数 | 16進数 |
| 0000 | 0 | 0 |
| 0001 | 1 | 1 |
| 0010 | 2 | 2 |
| 0011 | 3 | 3 |
| 0100 | 4 | 4 |
| 0101 | 5 | 5 |
| 0110 | 6 | 6 |
| 0111 | 7 | 7 |
| 1000 | 8 | 8 |
| 1001 | 9 | 9 |
| 1010 | 10 | a |
| 1011 | 11 | b |
| 1100 | 12 | c |
| 1101 | 13 | d |
| 1110 | 14 | e |
| 1111 | 15 | f |
この「16進数とは何ぞや」ですが、これは「2進数4ビット」の「別表現=影の表現」にすぎません; 2進の0と1ばかりでは読みにくくてしょうがないし、普通の 10進で書けば桁数がずれてしまって困る; だから、0000 .. 1111 までキリのよい 16個の「数字があることにして」、とりあえず「4桁を1文字で表現する」のです。「ない」数字は、仕方がないので a, b, c, d, e, f という字を当てた; それは、コンピュータを作ったのはアメリカ人だから、しかたがありません。
上の表の 16進が桁上がりするあたりだけ示すと、次のようになります:
| ◆◆◆◆ | 10進数 | 16進数 |
| 0000-1110 | 14 | 0e |
| 0000-1111 | 15 | 0f |
| 0001-0000 | 16 | 10 |
| 0001-0001 | 17 | 11 |
| 0001-0010 | 18 | 12 |
(似たような例には、「まんじゅう 12個で1ダース」があります。本日のまんじゅうの受注数 14ダース、合計いくつかわかりますか? コンドーム「1グロス」って、何個でしたっけ?)
文字コード(という数字)の表現には、しばしばこの「16進」が使われます。
「16進数」を使う理由は、「技術者にとって都合がよい」からです。他には、何の理由もありません。例えば、ASCII 大文字の 'A' と小文字の 'a' の関係は、
| 文字 | ◆◆◆◆ | 10進 | 16進 |
| 'A' | 0100-0001 | 65 | 41 |
| 'a' | 0110-0001 | 97 | 61 |
となっていますが、これは「上から3ビットめ(だけ)が0か1か」という「最少対立」関係です。従って「このビットを上げ下げすれば、大文字と小文字が入れ替わる」ことを、プログラマは理解しなければなりません。これは 10進数で表現しても意味をなさないし、この関係は 16進 の 41, 61 という姿ではじめて「ビットの並びかたが見えてくる」のです。
「何がわかりやすいのか」は、感性の問題にすぎません。ただ、技術屋さんの世界ではそうなっているので、文字コードの話は「何だかわけのわからん 16進数」が出てくる点が、講師としては苦しいところ。
いずれにしても、2進、10進、16進の関係は、「ある数をジューと呼ぶかトーと呼ぶかエーと呼ぶか」であって、その呼び方によって「数」そのものが変化するわけではありません。コンピュータの世界では、高い頻度で「技術者の都合による表現」がまかり通るので、やむを得ずこうして説明しましたが、何もユーザがこんな知識を振り回す必要はありません(事実、知ったかぶりのユーザというのは困りものだったりします...)。
ともあれ、次のことを理解してくだされば、本講の目的は達します:
(1) 文字コードとは、単なる数字のことである。
(2) この「数字」の表現におどろおどろしく「16進」が出てくるが、それは「まんじゅう 12個で1ダース」と同じである。コンピュータの 16進では、16個で1つ桁上がりする。
(3) どう表現しようが「数字」の値そのものに変化はなく、また そのコード=数字に対応して用意されているのが「フォント」である(本文参照)。
日本の JIS漢字/EUC、韓国の KS完成型
漢字やハングルになると「256文字」では追いつかないので、「連続2バイト」で表現することはもう書きました。
おそらく、読者は驚かれるかもしれませんが、日本の JISであれ 韓国の KS完成型であれ、その基本規格は「7ビット+7ビット」です。
どういう意味かというと、「2バイト」で表現することはするのだが、その上下各1バイトは8ビットをフルに使わず、実は7ビットしか使わない方針、つまり最上位ビットはいつも「0」で「規格」ができているのです。
これは、実は ISOのコード規格の指針があるからです。「2バイト」ではあっても、実際には「上下 各バイトの最上位は0」でコード系が展開されます:

で、具体的な JISと KSの標準2バイトコードを眺めてみましょう。
次の表は、今までとは異なって、タテ軸が 00-ffの上位バイト8ビット、横軸が下位バイト8ビットです。表の面積は 10進 256x256 = 65536文字ですので、上までの 4ビットx4ビットとは大きく異なる点に注意されたい:
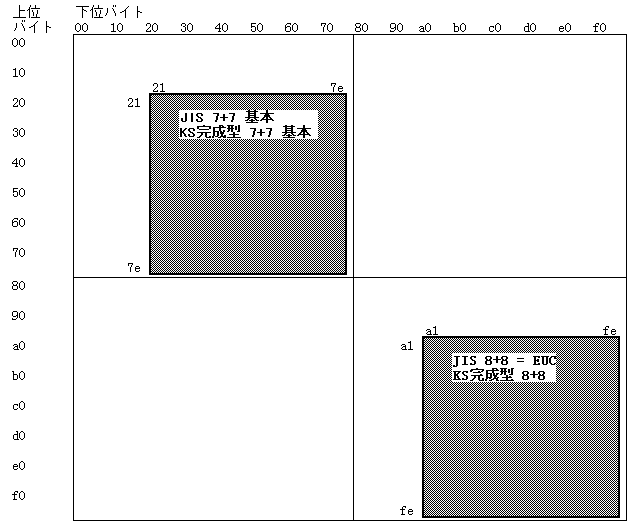
さて。
この表の左上の部分が、「7ビット+7ビット」、「本来の JIS漢字コード」域です。
頭のまわる人は、既に気がついていると思います; この「7ビット+7ビット」では、ある文字がアメリカの ASCII 7ビット文字なのか、7ビット+7ビットの JIS漢字や KSハングルの一部なのか、区別がつきません。
この解決に、ISOは「エスケープ・シーケンス」を使います; つまり「ここからは英文字、ここからは日本語、ここで日本語は終りで、ここから先はハングルだよ」といった一連の「制御文字」を用意して、テキスト本文に埋め込む方針を取ります。この実用例としては、日本語の internetメールがあります(だから、パソコンで internetメールを読んで、その内容を「パソコンのファイル」に「名前を付けて保存」するとファイルはできますが、パソコンでは この「制御文字」が解釈できないので、ファイルはしばしば「読めない!」ことがあります。解決策は、またいずれ)。
これでは「大変不便」という話は、当然 出ます。
7ビット系は英文字 ASCIIだけにしておいて、では ISOのコーディング指針を離れて「8ビットめをすべて1にしたらどうか」。そう考えたのは、日本の技術者でした。
先ほどの「7ビット+7ビット」のソロバンの絵は、上下バイトともに最上位が0でした。この際、それを「一貫して1にしたらどうなるか」。
それが、unixで使われる EUC (Extended Unix Code) です。これが、上の絵の右下の部分です。
こういうことにすると、7ビットx2で表現されていた「JIS漢字コード」が、すべて「8ビットx2」に移行します。別の言い方をすると、JIS基本漢字コード系は、EUC領域に別の「写像」を結びます。これらは互いに「写像」であって、従ってその内容は同一です。ソフトを作る立場から言うと、EUCでは、8ビットめが1の文字は必ず漢字の1バイトめまたは2バイトめなので、それなりの処理をすればよろしいと。
韓国では。
「KS完成型」と呼ばれる最優勢のコーディング系が、EUCと同じ方針を取りました。つまり、KS完成型の基本コード・セットは、7ビット+7ビットで定義されていますが、現実の運用においては「8ビット+8ビット」であり、これは日本の EUCと正確に同じものです。
この(俗称)「8ビットKS」は、韓国では Macでも Windowsでも、共通に採用されています。これと正確に同じ文字コード系 EUCが 日本では unixで採用されているので、実は、unixでは「単なるフォント切り替えだけで」、EUC日本語と8ビットKSハングルを随時・自由に切り替え、混在表示することが可能です。
日本の(unixではない、普通の)パソコンではどうなるか?
そこが複雑です。それが、次の「日本のパソコン Shift-JIS」です。
ただ、先走って「個人的」見解を述べておけば、
ISOのコーディング原則と、unixの EUC、韓国の「俗称」8ビット KS完成型コードとの関係は、上の絵でもわかるようにきわめて単純、明快であり、文字コード系として「実に美しい」ものに属します。
日本のパソコンの Shift-JIS
さて、と。
問題は Shift-JISです。何が「問題」かというと、「やたらと複雑」、言い換えると「スマートでない」、もっと言えば「とても汚いコード体系である」、に尽きます。
次の表が、パソコン Shift-JISのコード域です:
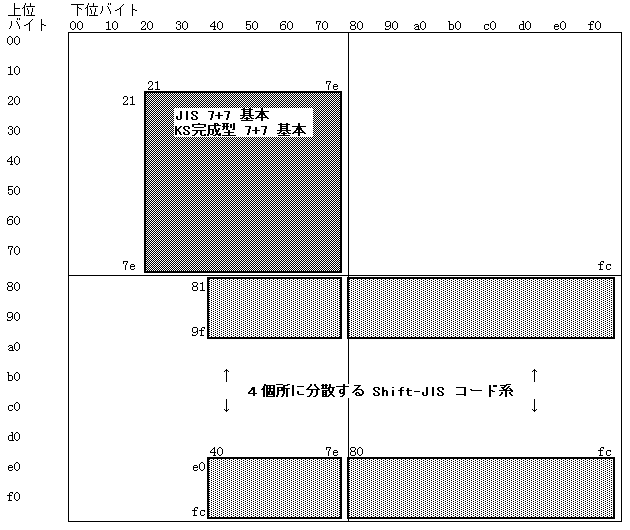
すぐ前の JIS-EUC, KS-パソコンKS の関係がすっきりしているのにくらべて、これはまた なんとしたことか。何が理由でこうまで複雑怪奇でなければならないか。
「理由」は、上の 「日本語 JIS(半角)8ビット系」で申し上げたように、「半角カナ」の存在にあります。
Shift-JISの表のタテ軸、a0, b0, c0, d0 (正確には a0 から df までの 64個)の部分が空白になっているのは、この範囲が「既に8ビットめを使っている既存の半角カナ」と衝突するからです。この「半角カナ」が存在する限り、JIS-EUC や韓国のパソコンKSの すっきりしたコード系は、使えません。
unixのように「日本語化」が遅れた世界では、かえって「半角カナ」など存在しなかったので、過去との互換性を考慮する必要がなかった。だから unixではすっきりと EUCを採用できた事情があります。
しかし、パソコンはそうはいかない。
JIS漢字コードができたころには、既に何十万台のパソコンが、街の会計処理に使われていました。そうしたソフトを温存し、さらに漢字を「追加する」形を取らざるを得なかった事情が、この「複雑な」、「汚い」コード系を生み出したのでした。
悲しいことに、日本ではまず「半角カナ」が、パソコンで「ある程度以上に普及してしまった」からこそ、パソコンの日本語はこれを無視できず、いつまでも「全角漢字と半角カナの共存」が要求されました。Shift-JISはそうして発明され、今でも半角カナは淘汰されることなく、ユーザが再生産されています。だからこそ、現在では「internetでは半角カナは使えません」と、口をすっぱくして言わないといけないのです。
追記 (1) Shift-JISの限界
Shift-JISもまた、本来の JIS 7+7 と互いに「写像」であることに変わりはありません。だから、Shift-JISが発明された当時の JIS漢字はすべて Shift-JISでも表示できますし、他のコード系 (EUC) との相互変換もできます。
ただし この2つの間の変換式は面倒で、1つの式ではすまず「4つの場合分け」、その上ですべて異なる式を使います。プログラムの素養のある人にはよい(?)例題ですが、しかし、あまり勧められる例題ではありません。もし必要があれば、既存のアルゴリズムを使うのが正解です。
Shift-JISのもう1つの問題は、ここまで複雑怪奇に発展してしまうと、既に拡張の余地がないことです。いわゆる JIS「補助漢字」や今後の JIS改訂には、Shift-JISでは対応できません。Shift-JISは、絶滅期のアンモナイト、マンモスや恐竜と同じです。だから Unicodeという勇ましい議論が出ますが、それはそれ、また別項で。
追記 (2) Korean Writerのハングルは Shift-KS
Korean Writerのハングルは、Shift-JISコード系の、単なるフォント・セットです。
ちょうど unix の日本語 EUCと 韓国パソコンの KSとは同じ領域にあるので、単にフォント切り替で相互混在できるのと同じように、Shift-JISのコード系に、韓国 KS と同じフォントを当てはめて行くと Korean Writerになります。つまり「Shift-KS」というわけです。
この KWテキストつまり Shift-KSテキストでは、もちろん 韓国パソコンと互換性がありません。高電社もそれは承知しているので、だから「KW <-> KS」変換ツールが付属しています。
追記 (3) KS と Shift-JISは混在できない
日本版 Windowsでは Korean Writer型のソフトでのみ、韓国の KS完成型「もどき」を実現できるにすぎません。
これは、WindowsというOSでは、文字コードの解析・表示の論理層 (文字コードの値によって「その文字」のフォント選択を行なう、上層ドライバ・ソフト。その下層にハードウェア・ドライバがある) を1セットしか持てないことに、よります。この「論理ドライバ層」は、そもそも日本版 Windowsにはじめから組み込んであって、取り替えがきかないのです。
従って、Shift-JISを期待しているドライバ層は KSの解釈に困り、また KSを期待している韓国版 Windowsのドライバ層は 必ず Shift-JISの解釈に矛盾を起こし、2つの文字コード系は決して同時に存在できません。
もし、OSに、「それらドライバ層のセットを複数持って、必要に応じて切り替える」機能があれば、テキストのある部分は韓国の(本物の)KS完成型、ある部分は日本の Shift-JIS、ということができる「かもしれない」けれど、現実の商品の Windowsに、その機能はありません。
その機能を、本当に実装したのは、Macです。
Macの KLKはなぜ日本語と混在できるか
Macの World Script II というOS内のメカニズムでは、「文字コードの解析・表示の論理部」つまりある種のドライバ層を、随時切り替えることができます。1つのドライバは Shift-JISだけを、また別のドライバは 韓国KSだけを、分担します。人間またはソフトがOSにある指示を与えると、この(ソフトウェア的な)切り替えスイッチが動きます。
このメカニズムを図式化すると、だいたいこんなふうになりますか:
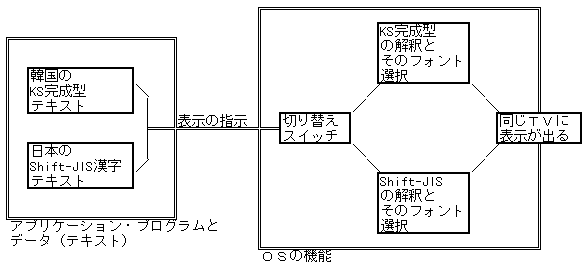
CLK, KLK, JLK をインストールすると、それぞれに固有のドライバ層、フォント・セットが追加され、「切り替えスイッチ」もロータリー・スイッチのように機能します。当然ながら、1枚のキー・ボードを使って、同様に(ソフトウェア的な)「入力装置」も切り替わります。
伝え聞くところによれば、Macのこの「多言語」キット(の個別言語セット)は数を増やしつつあります。その話を聞いた人から「いったい・いくつの言語まで共存できるのだ」という質問が出て、それには僕も回答できませんでした - おそらく、15ないし 16言語まで、次の境界は 255か 256言語まで、機械の能力の限界まで可能だろうとは思いますけれど。
KS完成型の文字セット (1)
上の講義(日本の JIS漢字/EUC、韓国の KS完成型)でも触れましたが、韓国の Windows/Macで採用されている「KS完成型」は、ISOのコーディング原則に従った「正統的な」文字コード系です。
この「正当な」、「正統的」なやり方には、実は困った問題があります - 文字数が、決して多く確保できないのです。
「16ビット・コード」を復習しましょう。
「8ビット」では、28 = 256個の文字を扱えました。「16ビット」なら、それは 216 = 65536個の文字を用意できるはずでした。
しかし、ISOの「2バイト」文字コード系の原則は「7ビットx2」でできています。日本の eucも、韓国の KS完成型も、基本的にはそれに従います。従って、現実の文字数は最大 214 = 16384個しかないのです。しかも、「ISO標準文字コード系」にはかなり大きな「予約」空間があって、その 16384文字さえ大きく削減されてしまうのです。
前に示した表を、再度掲げます(この表は、上の「日本の JIS漢字/EUC、韓国の KS完成型」と同じです)。表の全面を使えば 65536文字、しかしそれを4つに割れば 16386文字、しかしその「1/4」の空間さえ、図の上下左右が少しずつ削られて、だいぶ狭くなっていることに注目してください:
ISOのコーディング法では、左上と右下の2つの領域を「両方使う」わけにはいきません。どちらかひとつで自国の文字系を完結させて、一方は他方の「写像」とするしかないのです。
この、「自国の文字系」として完結する空間、いま右下の空間を取ると:

この空間は、計算してみると 8836文字しかありません - 原理的には6万余字があるはずなのに、それが4分され、さらに「現実の運用において」は半減して、実際には8千余字しか使えないのです。
8千余字のハングル ...一般論としては、充分な数ではあります。でも - 忘れてはいけない、韓国にも「漢字」が存在します。
KS完成型は、この 8836文字を「さらに!」いくつかに分割します。ある部分は記号類、ある部分は外国語文字、ある部分はハングル、ある部分は漢字に...
その結果、KS完成型の「ハングル」は、2350文字しか存在できなくなりました。
現代の韓国で使われているハングル字体は、2350文字で充分か?
それは、深刻な疑問が提出されました。その 2350文字を選定した人たちの苦労は、想像に余りあるものがあります。この人たちは、英断をもってその仕事に臨みました: まず、古典にある「古文字」は切り捨てる; 次に、幼児語や外来語にのみ見られる「特殊な」ハングル字体を切り捨てる。
だから、KS完成型のハングルの総目録には、古文字(例えば母音「アレア」を持つすべての文字)はありません; 「機械的な子音と母音とパッチムの組み合わせは可能だが 実際には存在しない」ハングル字体(例えば kaks)もありません(念のため neoksはあります); それから、外来語表記に使われる特殊な表記(ペプシ・コーラの pheph)も、ないです。
KS完成型のハングル文字セットは、そういう「きわめてラジカル」な切り捨てによって、たった 2350字というわずかな数の中に、「現代の韓国で使われる『ほぼ』すべての文字を網羅する」方針で作られたものです。この「2350字」という制限がどれほどきびしいものであったかは、例えば「在野」でしかなかった高電社の KOA TechnoMateが、当時の院生級を動員して 3000字以上のハングルを「厳選」していたことを思い出せば、明らかです。たった 2350字という制限の中で、現代語を表記すること - その「限られた資源」の中で選定された 2350字こそ、現代ハングルの「核心」ではあるのです。
ただ、90年代の初頭に作られたこの「KS完成型」の文字セットには、たしかに、深刻な欠落があるのは事実です。
例えば、当時の「国民学校」の1年生の教科書の冒頭に出てくる "ha-yaess-ta"(白かった(または「白いと第3者が言っていた」)伝聞形)の yaess が、KS完成型には ありません。
誰でも思いつきそうな、euis という文字が、やはりありません。これは「擬古文」の中でしか見られないので原則通りなのですが、しかし綴りの形式上は完全に現代語です。
いずれにしても/それにもかかわらず、この KS完成型は、現代の世界の Korean Languageの標準です。この文字系は韓国に限らず、日本でもそのクローンが数種類 販売されているし、Web-internet上のハングルのためには MicroSoft自身が KS完成型フォントを無料で配布しています。
さらに言えば、「北」の通信社である「朝鮮通信社」の東京からは、北の情報が Web-internetに、「韓国の」KS完成型ハングルによって発信されています。
「KS完成型」が、その意味で既に「世界を制覇した」ことは まちがいない事実です。
KS完成型は、既に世界の標準の地位を占めています。
この文字コード系に対する異議は、いろいろです。類型は3つです: (1) あらゆる種のハングルをコンピュータでは表現できない、これはハングルによる民族主義に対する愚弄である、(2) 擬古文字さえ表現できない KS完成型では、朝鮮語教育の現場で困る、どうしてくれるのだ、(3) UniCodeですべての言語問題を解決しよう。
(1) については、KS (Korean Standard) で定義されているもう1つの標準、つまり「KS組み合わせ型」ハングルの規格があります
(2) については、ワープロ「アレア」で解決できます。
(3) は、論者たちの水準を反映して、意味をなしません - 実は UniCodeのハングルは KS完成型ハングルのサブ・セットにすぎないので、現在の Windows/Macで出ないハングルは UniCodeになっても出ないのです。
上の3つの話題については、これからゆっくり解説します。
KS完成型の文字セットの見本を、次で示します。
KS完成型の文字セット (2)
既に「世界を制覇した」KS完成型文字セットは、上で説明したように、「初めから字数が足りないことを承知の上で」作られた文字セットです。
まず、この KS完成型セットの最初の 32文字を示します:

おどろくほど、びっくりするくらい簡素です。
しかし、「何か足りない」ような気がしませんか? では、次のものと比べてください。画像がやや汚いのはご勘弁:

実は、上の図は「KS完成型」そのもの、下の図は「KS組み合わせ型」です。前者がたった 32文字ですませているのに、後者はその2倍以上の文字数があります。後者には「現代ハングルの綴りで、実在するか否かにかかわらず論理的に可能なすべての文字」が網羅されています、が、その代り漢字は出ません。漢字をあきらめた上で、その領域すべてをハングルに捧げたのが「組み合わせ型」だからです。
あなたなら、どちらを取りますか? ただし「組み合わせ型」では、「世界に向けた Webホーム・ページ」上でハングルが文字化けし、それを Webブラウザで復元する手段はありません。
再度、強調します: KS完成型のハングル・セットは「初めから文字数が足りないことを承知の上で、厳選に厳選を重ねた」 2350文字です。だから、この文字セットからは、現代の韓国の「正常な」綴り法から導かれない・どのような字体も排除されています。例えば、kakk というハングルさえ、このセットからは排除されました(kakk というハングルを書きたいですか? それは 正しくは kkakk じゃありません? 床屋に行って散発するのは kkakk-neun-da であって、kakk-neun-da という単語はありませんよね)。
この「厳選」の結果として、KS完成型は世界を制覇しました。「ちょっと変った」ハングルの綴りは、この文字系では表現できません。その制限を抱えながら、しかし、この厳選に厳選を重ねた文字セットは、今では「北」の通信社のホーム・ページにさえ使われています。
KS組み合わせ型
すぐ上で説明したように、韓国でも世界でもメジャーとなった「KS完成型」文字コード系は、漢字・記号類とともにハングル 2350文字を持っていて、その 2350文字は「極限まで厳選された」ハングル・セットです。
実は、韓国内では、この 2350文字はぼろくそに言われていました。
だいたい、「完成型」の発想がおかしい; ハングルはそもそも 初・中・終の3声の合成で成り立つので、従ってコンピュータでもその原理で文字を構成するべし、それを、「ある文字コード1つに対してその字体」という対応をさせるのは、そもそも日本の模倣である。そういう論調がありました。
2350字だ? それ以外の文字はどうなるのだ; 民族の誇りであるハングルは、初・中・終のコードを決めれば「すべて」表現できるのに、2350文字に限るとは民族の誇りに対する重大な裏切りである。
云々。
事実、KS完成型が確定するまで、つまりコンピュータ各メーカーの規格が乱立していた時代、乱立した規格たちの主流は「ハングルの個々の字母にコードを与え、1文字のハングルはその3つの(4つの)組み合わせで決まる」タイプでした。乱立の主たる問題と解決策は、各メーカーが字母の選択・配列に歩み寄る意志があるかないか、それにかかっているように思われました。
しかし、政府規格はラジカルでした。字体は現代語に限定し、しかも現実に使われない字体は思い切って切り捨てて KS完成型 2350文字が決まった。一面「官」主導の強い韓国ではすべてのメーカーがこれに従い、互換性問題はたちまち解決されてしまう一方で、そのまた一面、野の民族主義はこれを許さなかった。なにしろ「コンピュータでは出ないハングル」があるのですから、許せるわけがないのです。
1992年の規格書 KSC 5601-1992 では結局、主文で KS完成型の解説と一覧を述べ、その後に「付属書 3 補助符合系(2バイト組み合せ型符合系)」が続いています。この「付属書」が、1970年代の初期8ビット機の時代から続く「ハングル文字コード系の乱立」に、一応の終止符を打つものになりました。
------------------------------------------------------------------------
話は、単純です。
ハングルの初・中・終の3つの部分にそれぞれ5ビットを与える; 5ビットなら 25 = 32 で、それぞれ 32字母(2重母音と2重子音を含む)を表現できる; 従って 5ビット x 3 = 15 ビット、残り1ビットを「これはハングル」記号に使えば、16ビット文字コードとしてどんぴしゃ。
この文字コード系はわかりやすく、例えばハングルの kak を表すコードは次のようです:
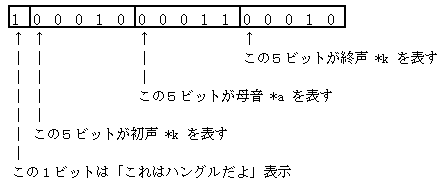
初・中・終声のそれぞれに 32種類の字母が可能ですから、それぞれの中にすべてのハングルが収まり、32ではまだ余裕があるので、将来的に古文字(擬古ハングル)を追加する余地もあります。
このやり方の欠点は、「ハングルだけで 16ビットを消費してしまう」ことです。従って、組み合せ型ハングルの文書には漢字は混在できないし、なんとテン・マルの類さえ書けないということになります。
いきおい、組み合せ型ハングルを使う文書では、(1) テン・マルの類はすべて英文字のカンマ、ピリオドですますか、あるいは (2) 完成型と一部混在させて「ここは完成型、ここは組み合せ型」という区別を、ソフトで別に扱うかの、いずれかです。
いずれにしても、「民族派」は、KS標準規格文書に「組み合せ型」を挿入させることに成功したわけです。この規格に従う限り「あらゆる種の、原理的に可能なすべてのハングル」が、最大3万2千字ほど使えます。
Windows 95以来の韓国版 Windowsの箱には、この「組み合せ型」ハングルが使えると書いてありました。ただ、困ったことに、僕は今でもその 韓国版 Windows 9x で「組み合せ型」を使う方法がわかりません。
現時点での結論的には、KS規格の1つである「組み合せ型」ハングルは、断固たる主張を行なった民族主義派を満足させるためのものでしかありません。
実例として、この KS規格に近い組み合せ型を採用しているのがワープロ「アレア」ですが、実は逆で、「アレア」勢力こそが KS規格の中に「組み合せ型」を明記させることになった最大の勢力だったのでした。その限りで、「アレア」は別に「国家規格」など必要としなかったはずですが、ただ、それを公式規格の一部に明記させることによって、みずからの正当性を確認したかった、はずなんです。
(注記:「アレア」の本当の内部コードは、正確には「組み合せ型」と異なります。「アレア」の内部コードについては、機会を見て別に説明します)
余談または冗談の (1):
「組み合せ型」を「組合型」と書くのはやめましょう。あれは「くみあわせ」型であって、別に労働組合が提案したものではないし、まして家畜飼料生産組合とは何の関係もありません。しかし、話者が日本人でかつ知識が不正確な場合、「組合飼料」と「組み合せ型の資料」が混同されることはあります。
余談または冗談の (2):
2進数/16進数の関係を理解した人は、5ビットで区切るコードの表現(読み方、16進で表示されたときの姿)が「ものすごく読みにくい」ことに気がついたと思います。
そう。だから、これは技術者自身にさえきらわれる面があること。その点は、記憶に片隅にとどめておいて損はないと思います。
UniCodeは世界を統一するか?
99年5月このページの記事は、誤りを含んでいました - 当時の記事に 「Unicodeのハングルは 現在の KS完成型の 2350文字だけである」 と書きましたが、これは正しくありません。
Unicodeの公式規格の目次(http://www.unicode.org/unicode/uni2book/uc20toc.html)には、次のようにハングルの領域が書かれています:
-
6.4 CJK Ideographs Area............6-103
- CJK Unified Ideographs: U+4E00--U+9FFF............6-104
- 6.5 Hangul Syllables Area............6-113
- Hangul Syllables: U+AC00--U+D7A3............6-114
(注意:上記は目次だけで、紙の規格書本体は US$59)
これによれば、Unicodeの漢字類は(最大)20992字、ハングルは(最大)11172字です。うーん・・・!
僕は、実は、(1) Unicodeの原規格上のハングルの字数(11172字)と、(2) 「internet上にある Unicodeによるホームページで現実に使えるハングルの字数(2350字)」を混同していたのです。
この問題は、やはり「Unicode以前に存在している各国の文字系」と、そこに乗り込んでくる Unicodeとの互換性問題、それにあたって Windowsや Macのソフトの一部が「Unicode対応」をうたいはじめたこと、さらに、実は 「既存の」KS完成型にも、Windowsでも Macでも 「独自の拡張」文字がからんでいて、問題を複雑にするのです。
Unicodeの「定義の上での」(ハングルの)文字数が 11172文字であるからといって、それが「今日現在のパソコンで、普通に全部 使える」わけではありません。11172文字の文字セットを表示するには、11172文字のフォントが必要であり、この「専用 Unicode」フォントは、99年7月時点で、少なくとも「普通の」エンド・ユーザの手に入るものではありません。仮に手に入ったとしても、「通信の相手方も同じものを用意してくれる」保証はないのです。
では、なぜ 「今・現在」Unicode(特に utf-8 コード系)によるホームページが存在したり Unicodeによるメールが可能かというと、末端のブラウザ側で次のような方法を取っているからです:
- Unicodeなので、特定の文字はそのコード値から「何語の文字か」は判別できる
- そこでブラウザは、次の行動を取る:
- MS-IE 4 以後の場合
- ハングルは Koreanフォントを、日本語は日本語フォントを、それぞれ使用する。Unicode国際域である漢字については、「その時点」でのデフォルト言語のものが使われる。
- Netscape 4 以後の場合
- 事前にユーザが 「Unicodeは何語のフォントで表示するか」を設定する。これに Koreanを指定すると、日本語も KS完成型のかな・カナ・漢字で表示される。逆に日本語フォントを指定すると、ハングルが出ない。
- (実は、Netscapeでは、いずれにしても表示はかなり悲惨なものです。これは別項で近日中に)
つまり、現状で Unicodeは「既存のコード系のフォントを流用して表示される」ので、従ってそこで表示されるハングルの文字数は基本的に 2350文字にすぎません。また、MS-IEのような自動判別という方針を取るならば、11172文字のフォントを別に用意しても何の意味もありません
まれに、Windowsでは「出るはずのない」(かつてのペプシコーラの) pheph が出たり、Macではまた別の字が出たりすることはありますが、それは(実は)Windowsや Macが「勝手に決めた」=機種依存文字であるにすぎず、「Unicodeだから出る」のではまったくないのです(こうした「勝手な拡張」は 文字系の話を複雑にするばかりなので、やめてもらいたいな。たとえば Macの「拡張」KS完成型は、1000文字もあったかしら)。
この話題は、Windows 2000? 関係ソフトの「Unicode タリョン」がどのようなものになるか、にも関連があると思うので、状況がもう少し進んできたら、再度 取り上げることにします。
また、既に存在する「Unicodeによるハングルのホームページ」の話題は、「1枚のページに同時に日韓2語が混在するホームページ」問題とともに、項目を改めて。
(このファイル終り)